Introduction
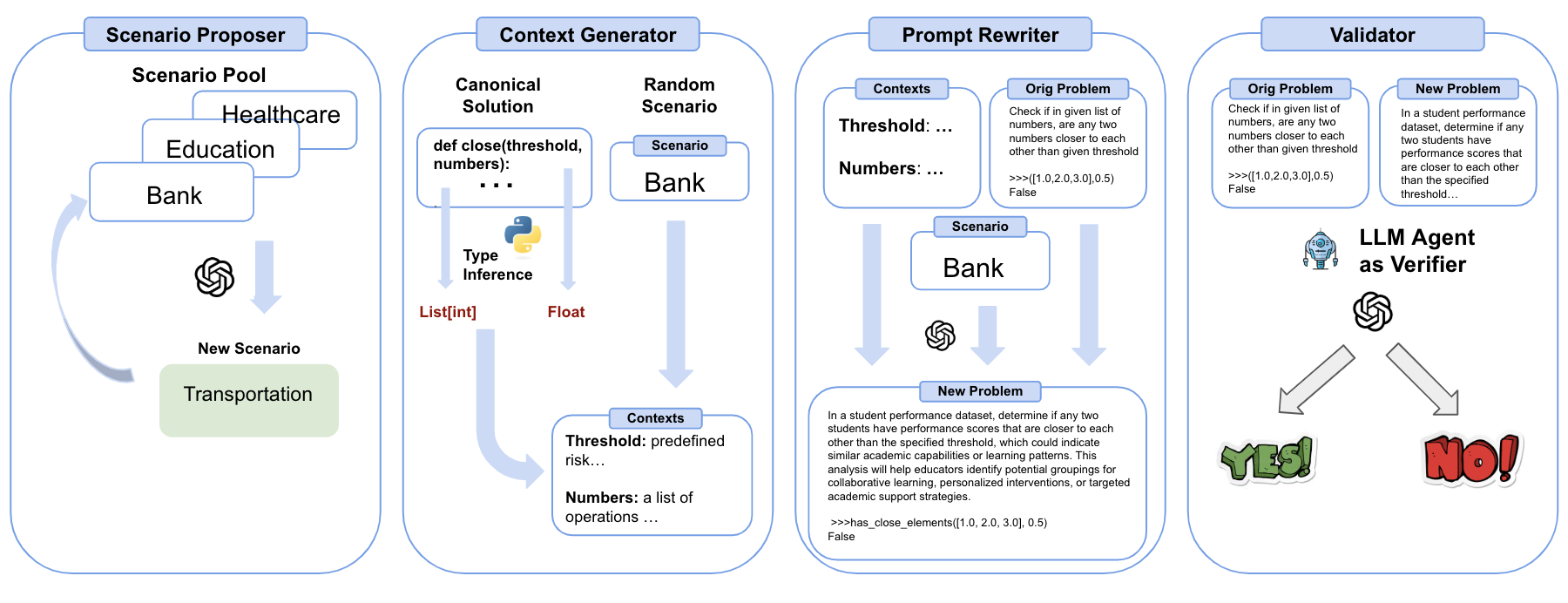
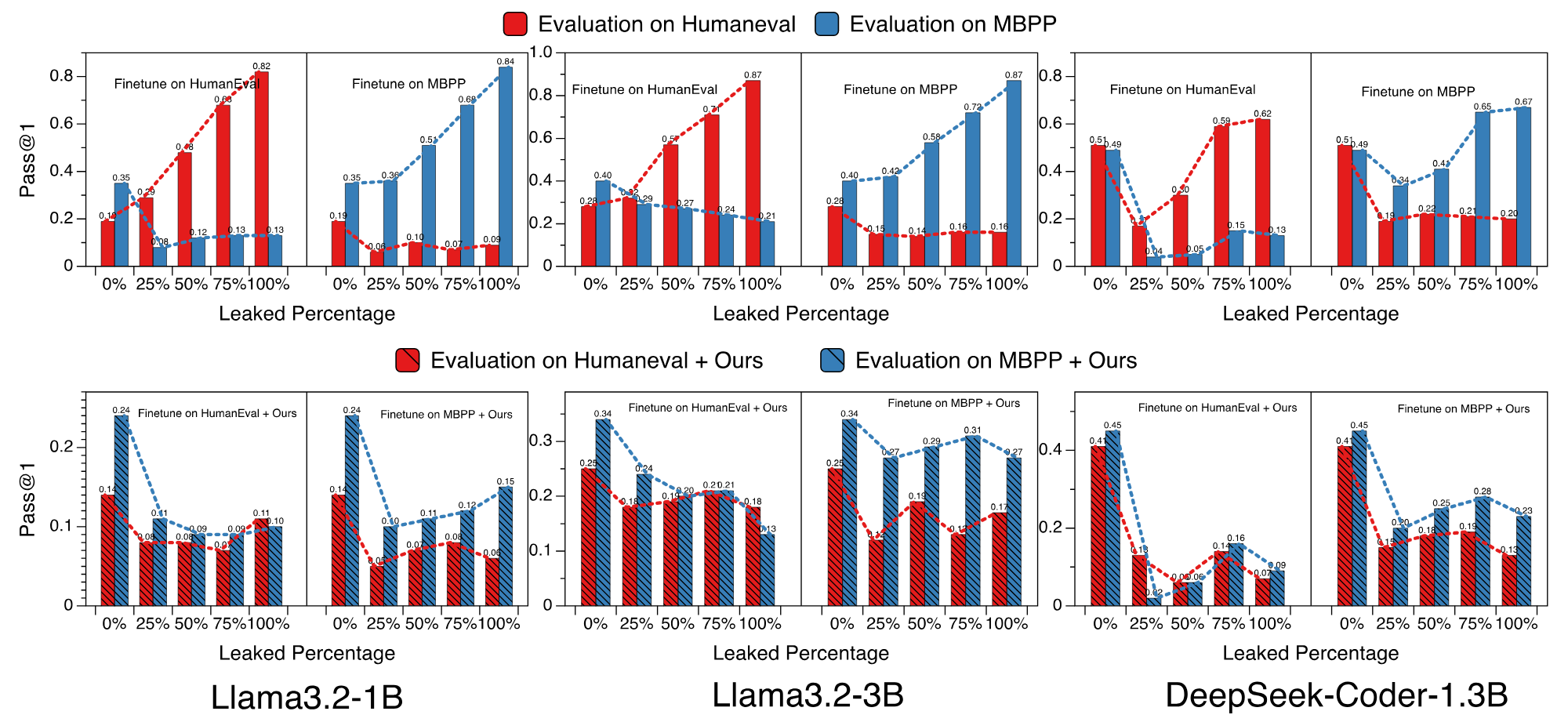
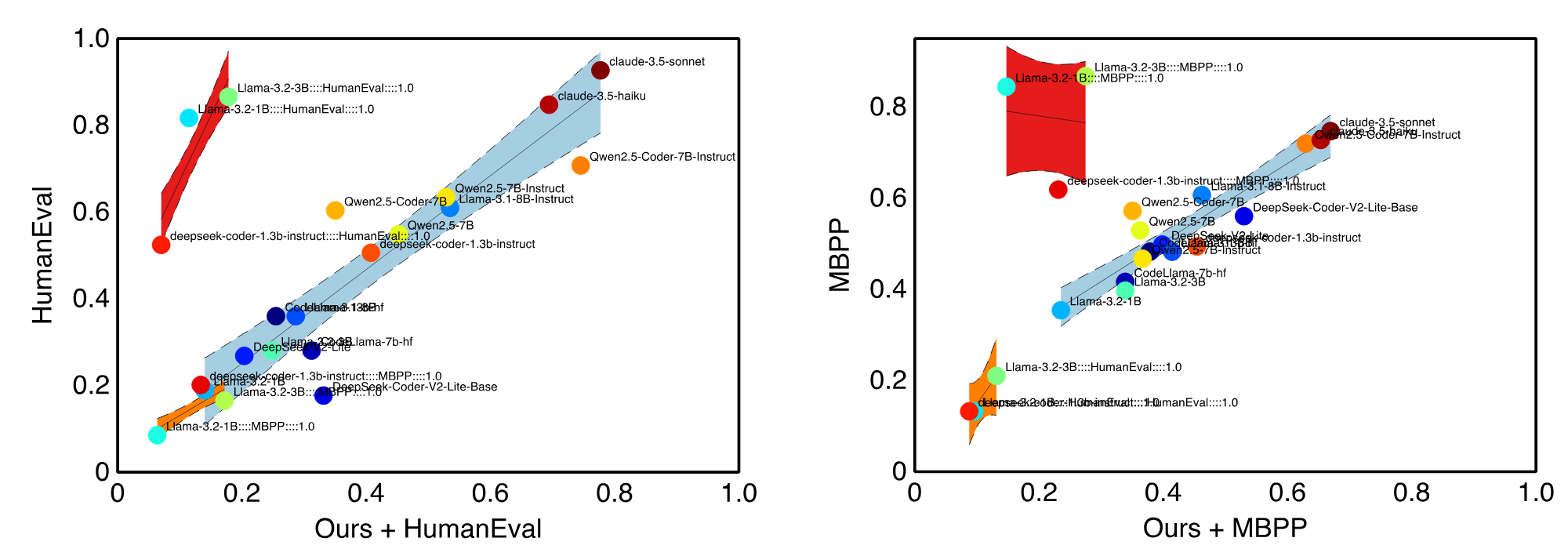
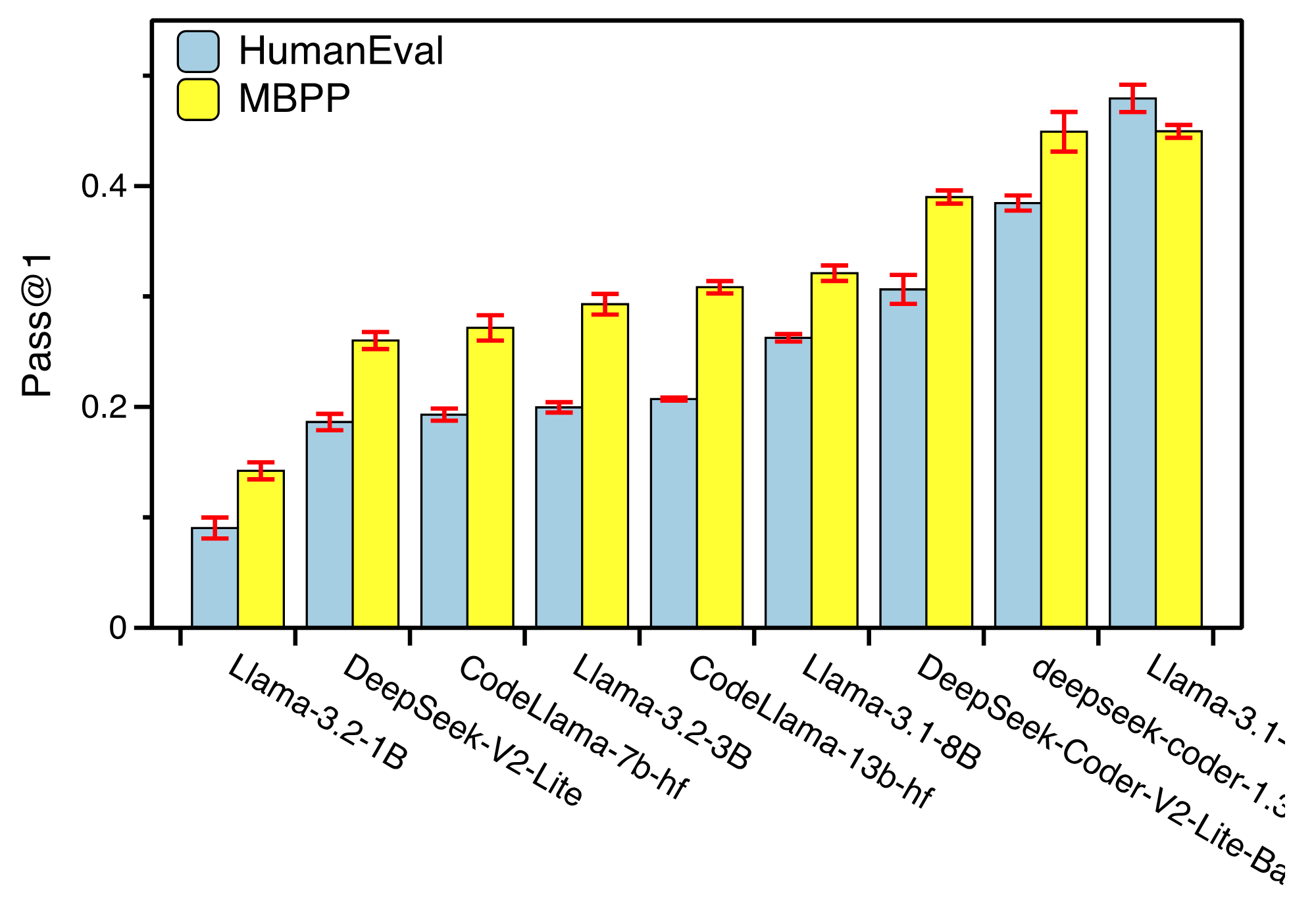
DyCodeEval is a novel dynamic benchmarking suite that employs multiple agents to generate a set of diverse semantically equivalent problems in order to provide transparent contamination-free evaluation on code LLMs. Below is an example of a problem that was generated by DyCodeEval from the seed programming problem.